![]()
Musika!
Fast Infinite Waveform Music Generation
Accepted at ISMIR 2022
An online demo is available on Hugging Face Spaces. Try it out here!
Find the paper here
Find the code here
Marco Pasini [Twitter]
Institute of Computational Perception, Johannes Kepler University Linz, Austria
marco.pasini.98@gmail.com
Jan Schlüter
Institute of Computational Perception, Johannes Kepler University Linz, Austria
jan.schlueter@jku.at
Abstract
Fast and user-controllable music generation could enable novel ways of composing or performing music. However, state-of-the-art music generation systems require large amounts of data and computational resources for training, and are slow at inference. This makes them impractical for real-time interactive use. In this work, we introduce Musika, a music generation system that can be trained on hundreds of hours of music using a single consumer GPU, and that allows for much faster than real-time generation of music of arbitrary length on a consumer CPU. We achieve this by first learning a compact invertible representation of spectrogram magnitudes and phases with adversarial autoencoders, then training a Generative Adversarial Network (GAN) on this representation for a particular music domain. A latent coordinate system enables generating arbitrarily long sequences of excerpts in parallel, while a global context vector allows the music to remain stylistically coherent through time. We perform quantitative evaluations to assess the quality of the generated samples and showcase options for user control in piano and techno music generation. We release the source code and pretrained autoencoder weights at this http URL, such that a GAN can be trained on a new music domain with a single GPU in a matter of hours.
Unconditional Techno Music Generation
We train an unconditional Musika system on a dataset of 10,190 techno songs from Jamendo. We use latent vectors from universal first level and second level autoencoders, both trained to reconstruct a wide range of audio domains.
We showcase short and long stereo samples generated by the system.
23 seconds samples










4 minutes samples
Conditional Techno Music Generation
We use the Tempo-CNN framework to extract tempo information from each song in our techno dataset. We then use tempo as conditioning for a latent GAN. This allows users to interact with the generation process by proposing a custom tempo before generating a sample.
We showcase samples generated using tempo conditioning spanning from 120 to 160 bpm.
120 bpm


125 bpm


130 bpm


135 bpm


140 bpm


145 bpm


150 bpm


155 bpm


160 bpm


Unconditional Classical Music Generation
We train an unconditional Musika system on a dataset of 1000 hours of classical music scraped from the internet. We use latent vectors from universal first level and second level autoencoders, both trained to reconstruct a wide range of audio domains.
We showcase long stereo samples generated by the system.
4 minutes samples
Unconditional Piano Music Generation
We train an unconditional Musika system on the MAESTRO dataset, consisting in 200 hours of piano performances. To decode the generated latent vector sequence, we use a second level decoder, trained specifically to reconstruct piano music, and a universal first level decoder, trained to reconstruct a wider range of audio domains.
Since the system is able to generate samples of arbitrary length, we showcase some short samples and some longer ones.
We also provide short and long samples generated by UNAGAN, which to the best of our knowledge is the only non-autoregressive music generation system able to generate audio of arbitrary length. While Musika generates stereo audio, UNAGAN can only generate single-channel audio.
23 seconds samples










4 minutes samples
UNAGAN samples for comparison
Conditional Piano Music Generation
We use the MADMOM Python library to perform onset detection for each sample in the MAESTRO dataset. We then create a note density signal and use it as conditioning for a latent GAN. This allows users to interact with the generation process by proposing a custom note density signal.
As a demonstration, we showcase generated samples created by both feeding random signals and using constant values as note density conditioning.
Random Note Density

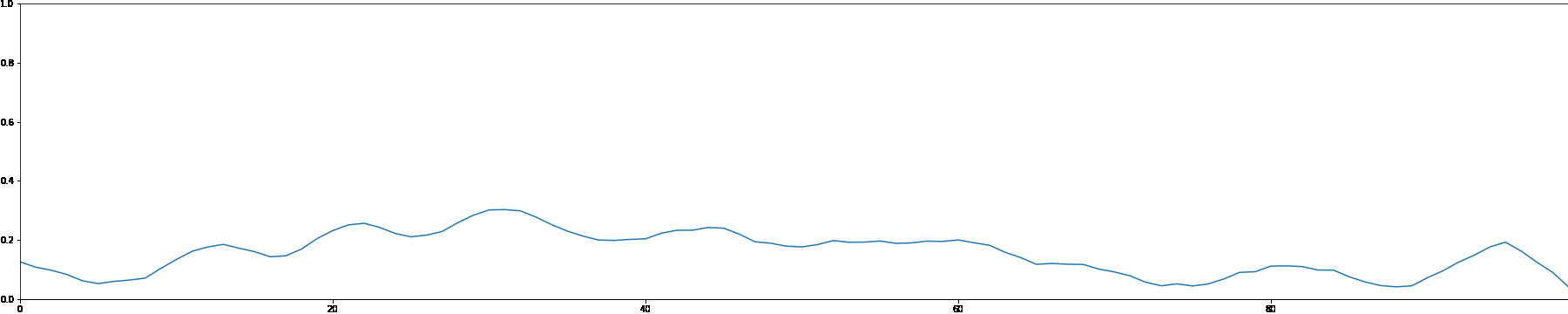

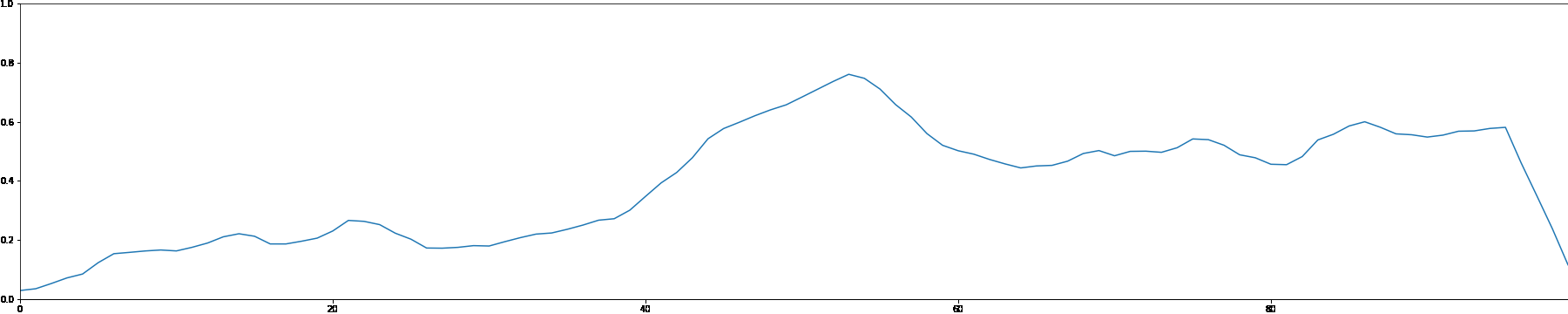

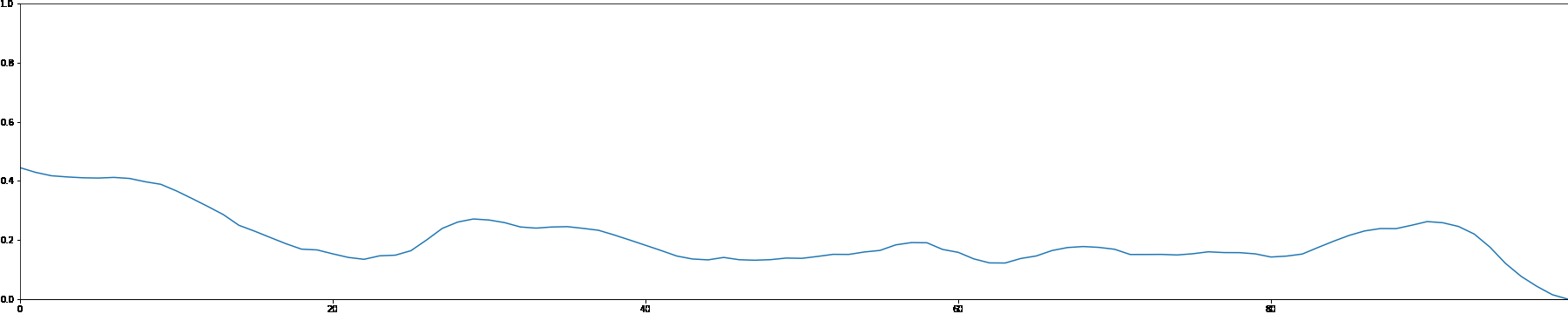

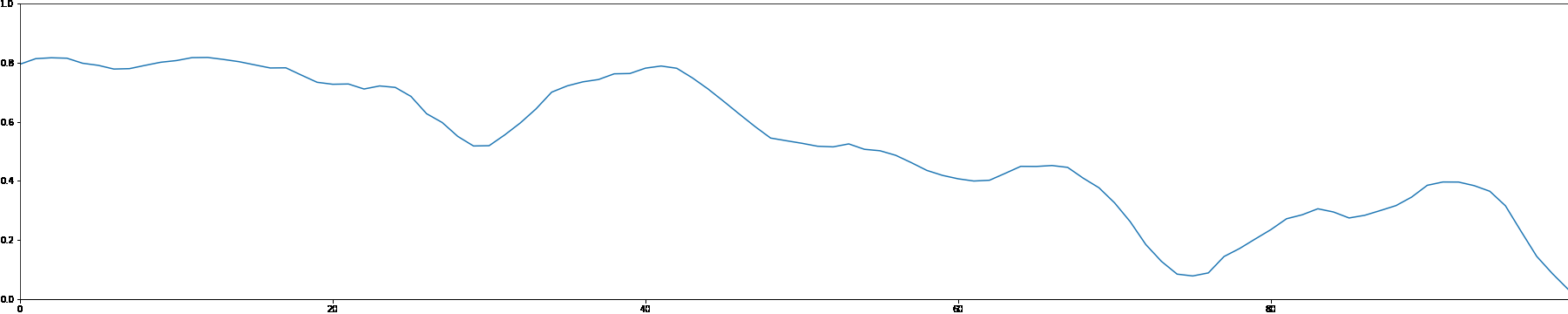

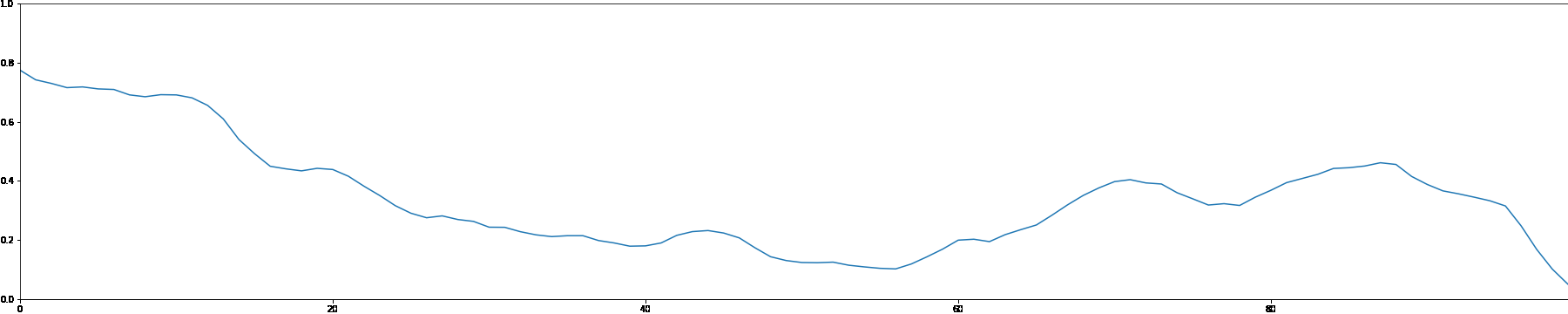

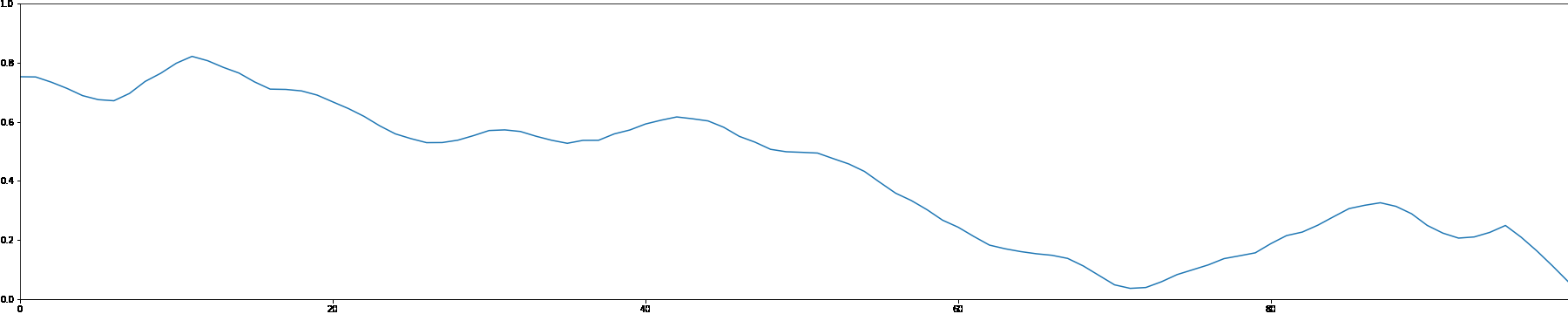

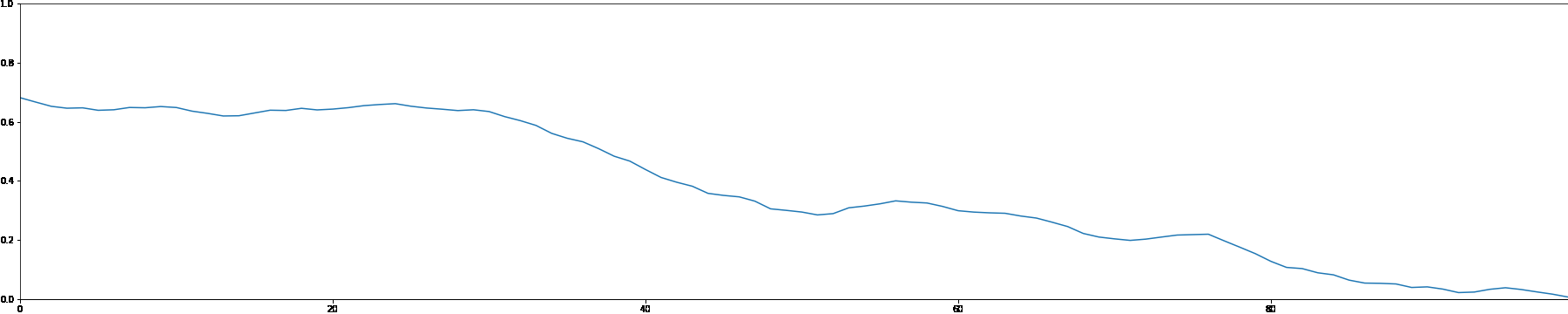
Constant Note Density